

Data poisoning has quickly become one of the most discussed risks in AI. As organizations increasingly rely on AI for critical business decisions, concerns are growing around the quality and integrity of the data used to train these systems.
In simple terms, data poisoning occurs when incorrect, manipulated, or malicious data enters a training dataset and influences how an AI model learns. Let’s understand this with a simple example- Your team has spent months building an AI fraud-detection model. The data is prepared, the model is trained, and testing shows excellent accuracy. Then, after deployment, fraud cases start slipping through unnoticed.
The problem is with data as thousands of fraudulent transactions had been incorrectly labelled as legitimate long before the model was trained, teaching the AI to make the wrong decisions from the start.
As AI becomes central to business operations from credit decisioning to threat detection to supply chain forecasting the integrity of training data isn’t just a technical concern. It’s a business risk, a compliance risk, and in some sectors, a safety risk. As per our analysis of AI-driven cybersecurity threats, data poisoning is already being deployed by sophisticated threat actors against real enterprise AI systems.
This blog explains exactly what data poisoning is, how attacks are carried out, what they cost when they succeed, and how to build defences before attackers peep in.
What is Data Poisoning in AI?
Data poisoning is a cyberattack that corrupts the training data used to build a machine learning model. By injecting mislabelled, or manipulated data before or during training, an attacker causes the model to learn incorrect patterns producing wrong & biased outputs when deployed in production.
Unlike most cyberattacks, data poisoning targets the learning process itself. The resulting model can appear to work correctly across standard benchmarks while being programmed to fail in specific, controlled ways that serve the attacker’s goals.
Table of Contents
How is data poisoning different from other AI attacks?
Data poisoning is a training-time attack. It corrupts the model before it’s ever deployed. Here are some ways in which Data Poisoning occurs-
Adversarial examples craft specially altered inputs that fool an already-trained model at runtime. They don’t alter the model itself, only the outcome for specific manipulated queries.
Model inversion attacks query a trained model repeatedly to reconstruct its training data. This is a privacy attack, not an integrity attack the model behavior isn’t changed.
Prompt injection exploits an LLM’s instruction-following behavior via malicious input at inference time.
How does Data Poisoning attacks work?
Data poisoning works by inserting corrupted samples into a training dataset before or during the model training process. Attackers exploit weaknesses in data collection pipelines, annotation workflows, and access controls to manipulate the data the model learns from. The attack surface spans the entire training pipeline, from raw data ingestion through preprocessing and labeling to fine-tuning.
Data poisoning doesn’t require an external breach. Internal actors like data engineers, annotation vendors, ML practitioners with pipeline access represent a significant threat vector. This is especially relevant for organizations running Shadow AI systems without formal access governance. External attackers who compromise data pipelines or annotation platforms also represent a realistic threat, especially for organizations sourcing training data from third parties or the open web.
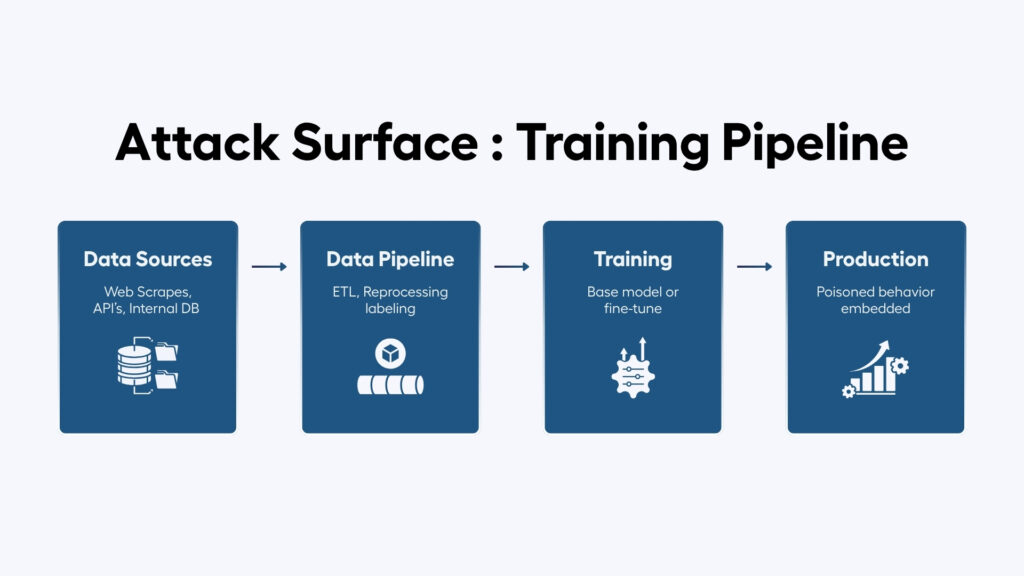
Agentic AI with autonomous agents that continuously learn from environment feedback face an increased version of this threat. Because they update their behavior based on interaction outcomes, a compromised feedback loop can degrade model behavior across thousands of iterations before it becomes visible.
How can organizations prevent Data Poisoning?
Defending against data poisoning requires layered controls across the entire ML lifecycle.
1. Data Validation and Sanitization
Firstly, apply anomaly detection, statistical filtering, and outlier analysis to all ingested training data before use. Flag samples with unusual label distributions or statistical properties that diverge from the expected data distribution.
2. Data Lineage and Version Control
Identify where each data point came from, who processed it, and what changed between dataset versions. This is both a detection capability and an essential remediation tool when poisoning is discovered, lineage tracking determines which samples to remove and which model versions are affected. Organizations on Microsoft Fabric have native data lineage capabilities that can accelerate this significantly.
3. Access Controls on Training Pipelines
Apply least-privilege principles across the entire data pipeline from annotation tooling and labeling platforms to feature stores and training infrastructure. Restrict who can write to training datasets, and audit access logs. Both insider threats and external actors require write access to execute most poisoning attacks, limiting that access directly reduces the attack surface.
4. Continuous Model Auditing
Monitor production model performance using slice-based evaluation testing outcomes across specific input subgroups, demographics, or conditions. Poisoned models often perform normally on average inputs while failing systematically on the precise inputs the attacker targeted.
5. Diverse Training Data Sources
Avoid single-source training datasets, sourcing data from multiple independent origins dilutes the impact of any single compromised source and forces attackers to compromise multiple pipelines simultaneously.
6. Robust Learning Methods
Incorporate adversarial training, differential privacy, and trimmed loss functions into the model training process. These techniques reduce sensitivity to individual corrupted samples and make it harder for small-scale injections to produce large behavioural changes.
7. Sandboxing for External Data
Apply sandboxing to fine-tuning pipelines that consume live data from external APIs, user feedback loops, or third-party sources. Treat unverified external data as untrusted by default, with validation gates before it influences model weights.
8. Adversarial Red-Teaming
Proactively test your ML pipeline and deployed models for poisoning with adversarial campaigns. This includes simulating label-flip attacks, data injection scenarios, and deliberate backdoor trigger testing.
Data Poisoning Prevention for Enterprise AI
Sparity’s AI security practice is built around integrated, defense-in-depth security that covers the full ML pipeline rather than a single checkpoint. Our approach to AI-driven cybersecurity threats applies directly to detecting the behavioral signatures of poisoned models.
We implement data lineage, access governance, and audit controls within your existing data estate whether you’re running a Microsoft Fabric-governed data platform or building Agentic AI workflows on Databricks. Both platforms have native capabilities we know how to leverage for ML pipeline security.
As enterprises deploy autonomous AI systems, we architect feedback loops with integrity controls that prevent continuous learning from becoming a continuous attack surface.
Data poisoning defense starts before your first model is trained. Sparity can help you build the governance infrastructure, monitoring systems, and security posture to keep your AI trustworthy from first data point to production inference.
Request a Security Assessment →
FAQ’s
What is data poisoning in AI?
Data poisoning is a cyberattack that corrupts the training data used to build an AI or machine learning model. By injecting false, mislabeled, or manipulated data before training begins, attackers cause the model to learn incorrect patterns producing wrong, biased, or attacker-controlled outputs in production.
What is the difference between data poisoning and adversarial attacks?
Data poisoning targets the training phase it corrupts the data a model learns from so the model itself is compromised before deployment. Adversarial attacks target the inference phase they craft inputs that fool an already-trained model at runtime.
Can large language models (LLMs) be poisoned?
Yes, and LLMs are particularly exposed. Models trained on web-scale datasets can be influenced by strategically crafted content published online before the next training crawl sometimes called web poisoning.
How do I detect if my AI model has been poisoned?
Detection requires slice-based evaluation across specific input subgroups, behavioral drift monitoring in production, and deliberate red-teaming with adversarial test cases.
Is data poisoning a compliance risk under AI regulations?
Yes. The EU AI Act requires training data traceability for high-risk AI systems. NIST’s AI Risk Management Framework includes adversarial robustness as a core trustworthiness dimension.
FAQs



